Overview
Lip reading is the skill of understanding speech from lip movement alone. Automating it could support communication for people who are hard of hearing, power automatic captioning, and even drive the mouth of a virtual avatar. The goal of this graduation research was to "make a computer read lips" — recognising words from visual information only, with no audio, and feeding the result into caption generation.
Conventional image-based methods (CNN-based) reach high accuracy but are computationally expensive. This project instead took a landmark (feature-point) based approach, using only facial landmarks as input to keep compute low and aim for better generalisation.
Pipeline
- Prepare the dataset
- Extract and scale facial landmarks
- Build and evaluate the model
- Generate captions
Dataset
The Oxford-BBC Lip Reading in the Wild (LRW) dataset — 500 words spoken by over 1,000 speakers in natural "in the wild" conditions (256×256, 29 frames each) — split into training, validation, and test sets.
Landmark extraction & scaling
dlib's shape_predictor_68_face_landmarks extracts 68 facial landmarks per frame. One mouth point is fixed to a
reference coordinate (128×128), the remaining points are placed relative to it, and everything is scaled against the nose
position to normalise for speaker and position. Each word is labelled (ABOUT → 1, ABSOLUTELY → 2, …). The processed input is a
time series of [29 frames] × [20 landmarks] × [(x, y) coordinates].

Model (LSTM)
Because lip motion unfolds over time, I used an LSTM (Long Short-Term Memory) network, well suited to sequential data. On top of the input layer (29 frames × 20 landmarks × 2 coordinates), two stacked LSTM layers (64 and 32 units) were used, with ReLU and Softmax activations and dropout (0.5) to curb overfitting.
Results
Training accuracy climbed to around 60%, but validation accuracy stalled at roughly 0.2% — the model could barely classify unseen data. The loss curves tell the same story: training loss fell while validation loss kept rising — a textbook case of overfitting. In the end, it never reached a level where captions could be produced.
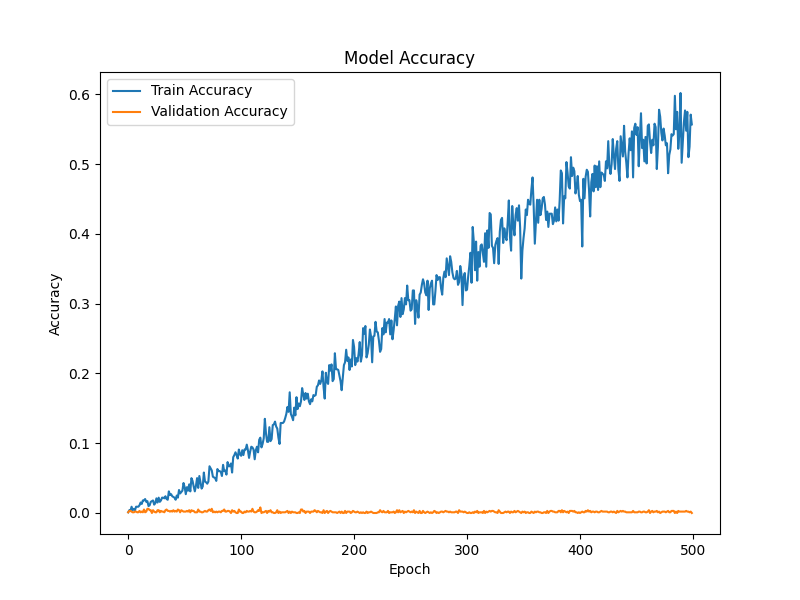
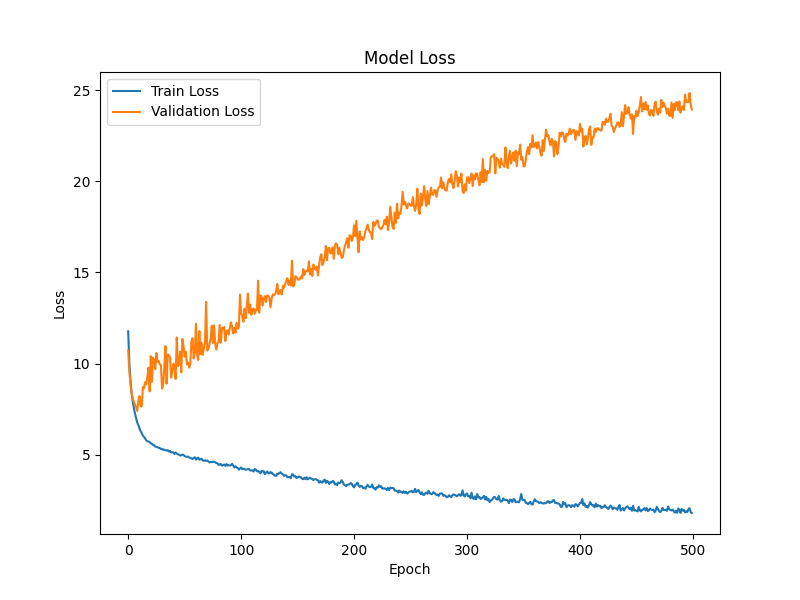
Discussion & next steps
Increasing the dropout rate, adding L2 regularisation, revisiting which landmarks to use (mouth-only vs. all 68 points), and toggling scaling all failed to improve validation accuracy. The likely conclusion is that the temporal trajectory of landmark coordinates alone does not carry enough information to distinguish spoken words. A promising next step is to introduce models such as a GCN (Graph Convolutional Network) that can capture the spatial relationships between landmarks at a higher dimension.
Even though the result fell short, the real value of this project was driving the full research process end to end — framing the problem, building the data pipeline, designing and training the model, and evaluating and reflecting on the outcome.